Harness Engineering: 4 Levers to Diagnose Any AI Agent
Most agent failures aren’t model failures. They’re harness failures.
I break down the four levers I use to diagnose agents in practice: context, tools, loop, and governance. If an agent grabs the wrong information, calls the wrong tool, loops too long, or stops too early, this framework tells you where the harness failed and what to fix first.
Building an AI agent?
I help teams design and ship agentic systems — from architecture to production.
See how I can help
Building a Software Factory: How Much Should You Delegate to the Agent?
A software factory is not all-or-nothing autonomy. I build a read-only Dependabot triage agent in Mastra and show where delegation should start.

I Added ACP to My Mastra Agent So It Can Work in Repos
ACP is the layer that lets my Mastra agent hand real repo work to Claude Code instead of stopping at advice.

Stop Giving Your Agent Every Tool
Large tool catalogs break agent context. Tool search fixes that by letting agents discover and load only what they need.
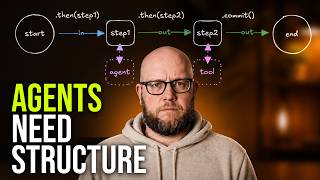
Stop Letting AI Agents Run the Whole Workflow
One inbox agent should not classify, research, score, route, and draft replies in one loose loop.
Get new videos and posts by email
Weekly videos on AI engineering, plus deeper dives in the newsletter.
Occasional emails, no fluff.